I was recently talking to another developer about the importance of never exposing internal identifiers to the outside world. A well-known example of this is using an auto-incrementing identity field in SQL and exposing that field through an API. A client can look at the highest number to tell how many records exist, in an ordering system this is far from ideal. Now everyone will know how many orders you have created. I recommend watching The Internet of Pwned Things by Troy Hunt for a real-world example.
One way to avoid the problem above is by simply hashing/encoding your identifiers. You can use a UUID but as Planet Scale points out in their Why we chose NanoIDs for PlanetScale’s API blog post, UUIDs don’t provide a good developer experience. As an API developer, I want to provide the best DX possible.
I started thinking about the process of hashing identifiers, and I wanted to build one from the ground up to expand my knowledge and understanding. Now I could build a C# version of the nano id implementation, but that already exists. Instead, what I will do is tackle another known problem, URL shortening. The idea here is to take a URL like https://www.yunier.dev and convert it into something like https://tinyurl.com/yckpk37h, where yckpk37h is more than likely the hashed representation of the internal identifier in the database used by TinyURL. I’m honestly guessing here but I know that is how a typical URL shortening system is built.
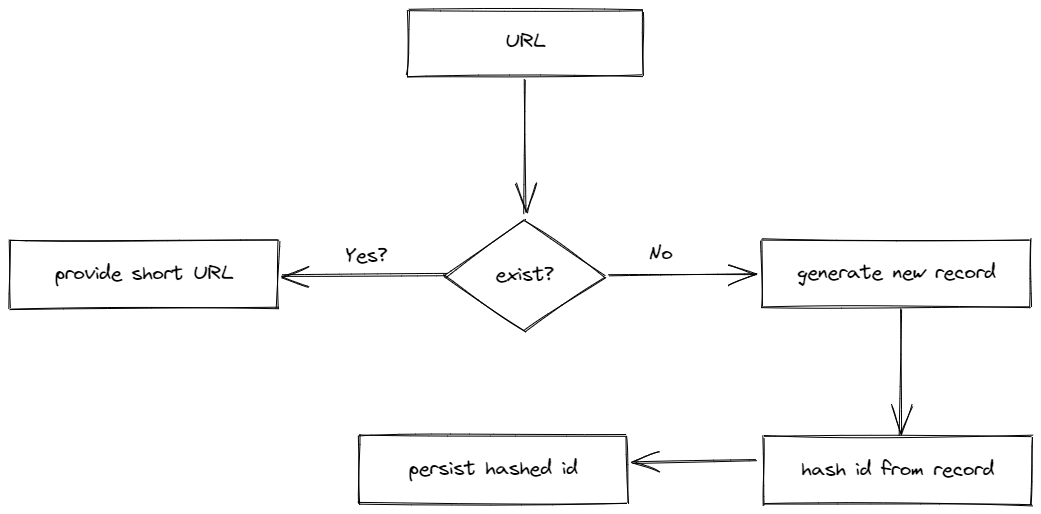
The process of shortening a URL can be broken down into the following steps.
- Check if the URL provided exists, which means we have probably already shortened it.
- If the URL has previously been shortened then return the short URL.
- Otherwise, create a new record, which creates a new identifier.
- Hash the identifier to get the long URL.
- Save the short URL and return it.
The following diagram provides a high-level overview of the process described above. The diagram was built using Excalidraw.
I want to implement steps three through five. I’ll start by creating a new .NET 6 project that will write and read from a SQLite database, I picked SQLite to keep things simple. The SQLite table structure consists of three columns, an identity column, the hashed column to store the hashed id, and the URL column to store the original value. Here is the markdown representation of that table.
| Id | Hash | Url |
|---|---|---|
| 100000 | q0U | https://www.yunier.dev/ |
| 200000 | Q1O | https://en.wikipedia.org/ |
| 300000 | 1g2I | https://gohugo.io/ |
The first step in building my own hash function is to decide which characters can be used by the hashed function, essentially I need an alphabet. For a URL shortening service an alphabet composed of the numbers from 0 to 9, the letters a to z, and A to Z is generally considered good enough, it means that the alphabet will be composed of a total of 62 characters. One of the most important aspects of a good hashing function is that the function should properly handle collisions. By using Base62, collision will be impossible because the conversion is consistent, there will never be any duplicates.
The next step I need to take is to determine how many URLs can the application support while keeping in mind that as of 2017, SQLite has a limit of 140 terabytes. URLs tend to be pretty long, but for the sake of simplicity, I’m going to build the system under the assumption that on average an URL is roughly 200 characters long which translates to each URL consuming roughly 200 bytes. The next assumption that I will make is that the service will be around for 20 years and that it needs to support at least 1 billion URLs.
So that is 200 bytes times 20 years times our 1,000,000,000 minimum requirements gives 4,000,000,000,000 bytes or 4TB. 4TB is well below the 140 terabytes limit of SQLite and allows plenty of room in case the application needs to scale beyond these assumptions.
In the last step, the most important, I need to understand what is required to build my own Base62 function. Luckily, the internet is full of knowledgeable people like Matthias Kerstner and in his blog post Shortening Strings (URLs) using Base 62 Encoding he provides the algorithm to create a Base62 hashing function, you can find his algorithm below.
| |
The algorithm can be translated into the following C# code.
| |
Now that I have the hash function defined all that is left for me to do is to add it to a service class and inject that service into my controller. For example.
| |
I think I have everything that I need, time to test the API by sending the following command.
| |
Executing the command above yields the following JSON response.
| |
with the following HTTP response headers.
| |
Perfect, the API is working as expected, it accepted a URL, it provided a hashed which can now be postpended to a URL to create something similar to https://tinyurl.com/yckpk37h. In an upcoming blog post, I’m going to go deeper into hashing, I’ll explore hashing techniques and different methods and how to create a hashing function with a low collision probability.